DeepSeek该如何选型GPU
DeepSeek场景下GPU选型的3个重要因素:
最近随着DeepSeek一体机需求的持续火爆,大家讨论最多的话题之一就是怎么选择合适的GPU(严谨一点的说法是AI芯片,因为很多国产加速卡是ASIC架构,并非GPU架构),和以往智算中心千卡万卡训练集群不同DeepSeek部署属于推理场景,如何选择更合适的GPU卡呢?今天结合个人浅见从3个方面简单聊聊!
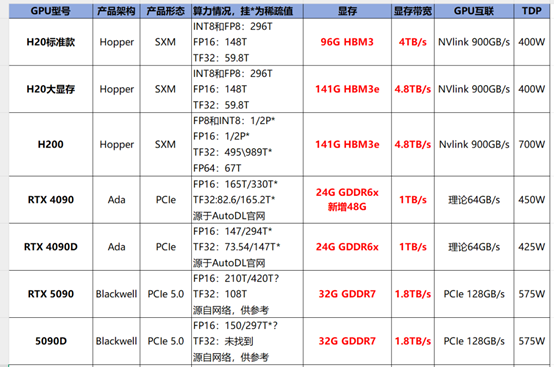
一、GPU显存参数(大小、类型和带宽)显存的大小决定了能“装下”多大参数量的模型,比如DeepSeek R1满血版671B在FP8精度下,模型加装就需要671G显存容量(实际运行还需要考虑KV cache和激活参数的显存占用等),目前最热门推理GPU是H20 141G版本、4090标准版和48G显存版,我个人整理的表格如下(供大家参考),除了显存大小外,显存类型和显存带宽也很重要,比如H20 141G采用了HBM3e显存带宽高达4.8TB/s,显存的高带宽可以提升更短的每token延时以及总并发数。
二、GPU卡的精度支持与训练场景不同,推理场景在计算精度上要求略低(训练通常需要FP32或FP16,推理通常需要FP16、FP8或Int8),FP8是8位浮点数据格式的意思,市面上在售的各类DeepSeek一体机都宣传支持满血版R1,但如果其实配的GPU卡支持的算力精度不同,“满血版”的实际效果也是不一样的,下图是截自“特大号”文章里的图片,我觉得非常形象。
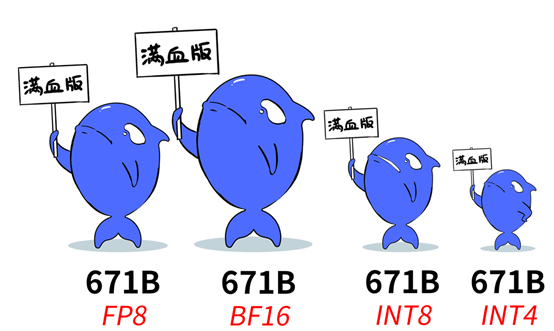
DeepSeek官方资料里推荐的精度是FP8和BF16,但其只提供了FP8权重的满血模型,如果采用BF16权重模型需要自行转换,按照官方说法采用原生支持FP8精度的GPU来部署是真正达到满血版效果最优的选择。但并非所有的GPU都支持FP8,如A800和很多国产卡就不支持,就需要做BF16或FP16精度转化,精度虽然无损,但对算力系统开销会增大,推理效率会降低。也有采用Int8和Int4量化版的方案,虽然能跑但是效率上提升了但是由于模型精度的降低会导致“智商下降”,具体表现是“提示词”一样,但是输出的结果和“DeepSeek官网的满血版”有明显差距。H20、L20和L2等型号都原生支持FP8精度。

英伟达Ampere架构的A100或者A800下图所示是不支持FP8精度。
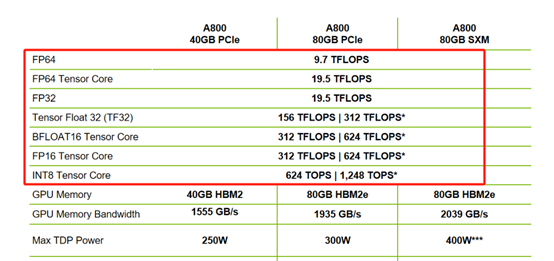
随着大模型技术的逐渐演进可能会迭代到FP4精度,英伟达最新发布的50X0系列产品,第五代Tenser Core已经支持FP4精度计算,如下

三、GPU计算性能与并行能力
虽然单台H20 SXM整机可部署满血版(性能与成本的黄金平衡),但是并发数有限,基于不同厂家的公开数据可支持10~100路并发不等,总的Token/s在1k~2k(调优能力不同有差距),如果要满足更高并发需要采用多机集群的方式部署。
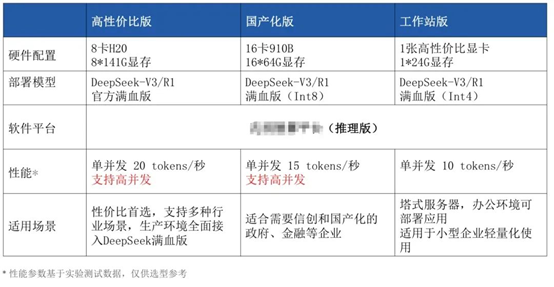
下图是某云厂商DeepSeek满血版不同机型配置的性能情况,供参考: