提供计算、存储、网络的配置、监控、巡检、告警等能力,同时提供大模型调优服务

+86-15999624503
service@stone-stem.cn
深圳市南山区
南山街道荔湾社区前海路0101号丽湾商务公寓A-515
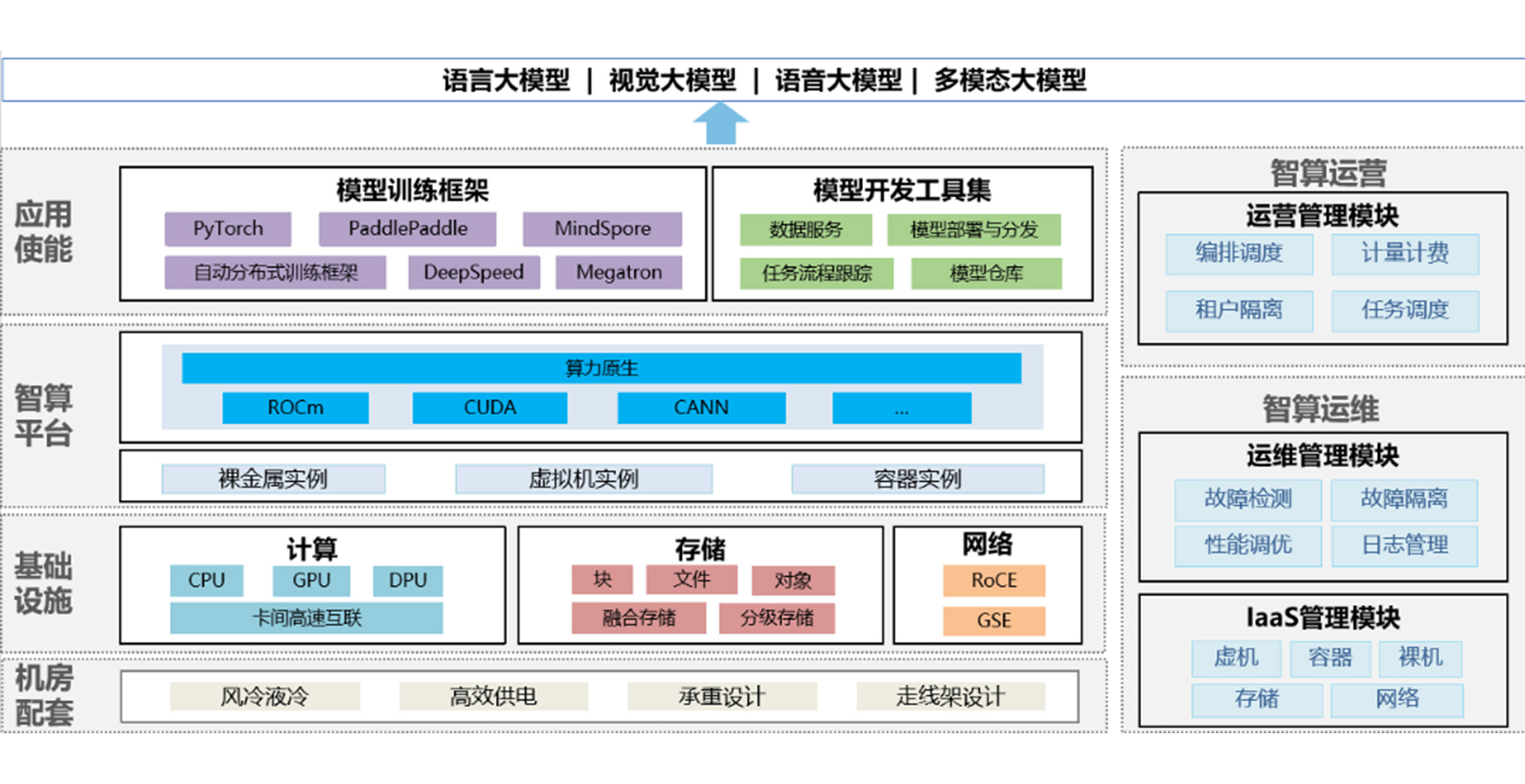
提供高性能服务器供应及智算集群专业运维,面向新基建、新算力提供高性能GPU服务器与高速网络交换机与通信组件
支持大模型智算平台和端网一体运维监控平台,能够实现端网融合、异构融合、软硬融合、城域融合,为客户提供智能算力规划、选型、建设、管控、调度、运维一站式服务。
目前已落地十余个千卡以上的智算集群,在集群落地过程中通过网络自动化、网内计算和分布式计算通信等核心技术,实现超异构、超互联、高稳定、高均载、高扩展
提供计算、存储、网络的配置、监控、巡检、告警等能力,同时提供大模型调优服务
可实现不同GPU算力的互联互通,支持单一大模型训练任务在异构GPU资源池上的联合计算,做到了规模突破,支持超大型GPU集群训练,全栈且深度融合带来端到端优化,助力超算互联工程。平衡算力需求与供给,实现高精度到底精度全覆盖、多种计算类型全覆盖,以及AI训练+推理全覆盖。
端网融合
异构融合
软硬融合
城域融合
实现不同GPU算力的互联互通,支持单一大模型训练任务在异构GPU资源池上的联合计算,做到了规模突破,支持超大型GPU集群训练,全栈且深度融合带来端到端优化,助力超算互联工程。平衡算力需求与供给,实现高精度到底精度全覆盖、多种计算类型全覆盖,以及AI训练+推理全覆盖。同时团队在异构服务器集群的搭建上取得了一定进展:异构服务器,具备多个集群异构组网经验,如CPU异构:不同GPU服务器CPU异构(AMD与Intel异构)其大规模组网会出现网络不通等问题,通过替换底层通信库解决此问题;GPU异构,解决800系列与100系列的异构问题,使得A800与A100,H800与H100可以实现混跑组网,其同样通过替换底层通信库来实现;服务器异构,不同品牌的服务器的内在拓扑逻辑存在着不通,这使得多品牌服务器可能无法混跑,或者性能受损失。通过改变底层通信库建链逻辑,团队组建集群可实现多品牌服务器共同混跑,且性能无损失。
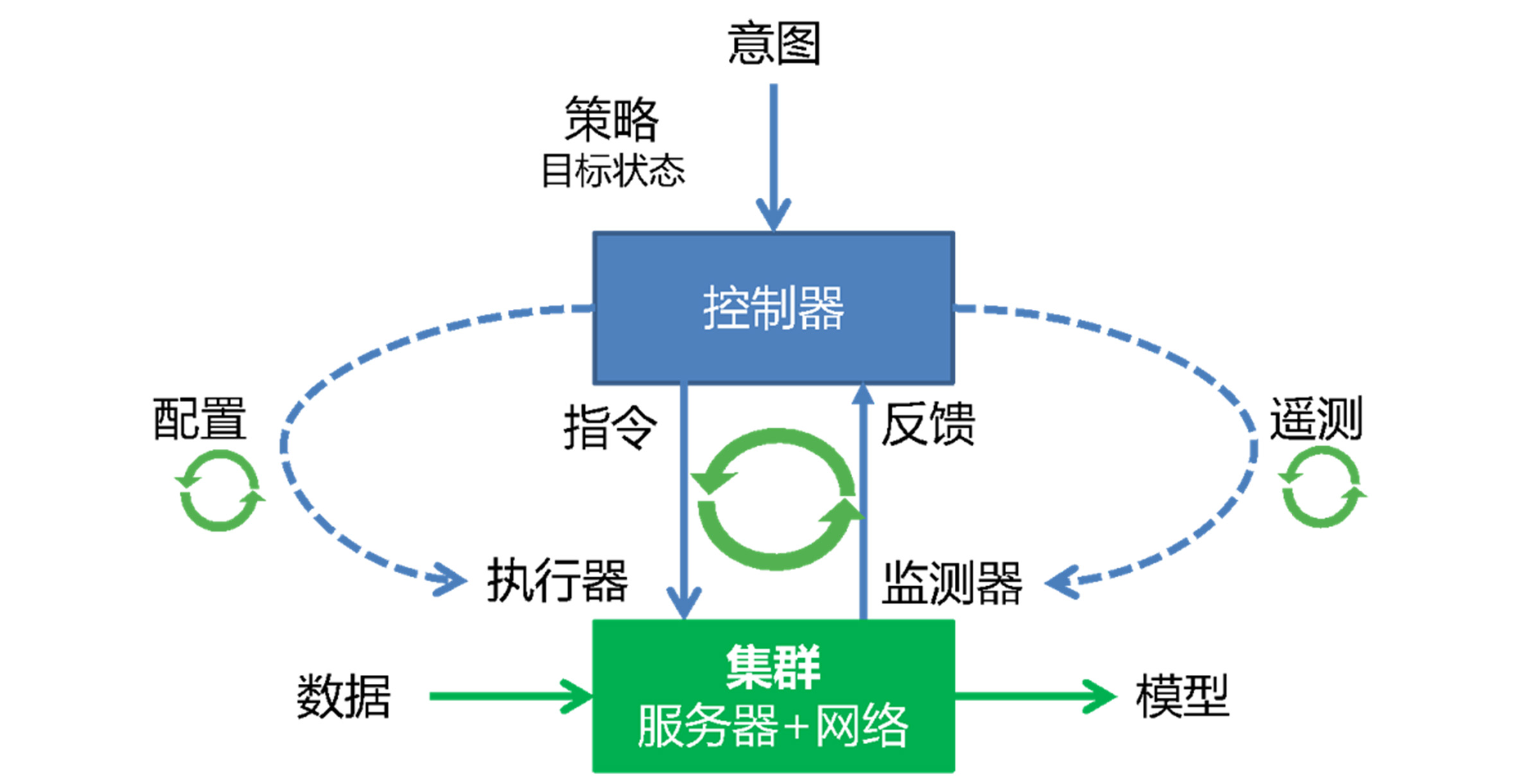
提供计算、存储、网络的配置、监控、巡检、告警等能力,同时提供大模型调优服务,从集合通信库、训练框架、并行策略等多方面协助客户进行调优。